Алгоритмы Хранения Данных
Метод структурированного хранения, берет на себя все эти вопросы. Он появился в 1980-х годах, однако в последнее время видим все более широкое использование этого метода в качестве способа структура хранения в движках баз данных. В своем первоначальном применении файловой системы, она страдает от некоторых недостатков, которые препятствуют широкому распространению, но, как мы увидим, они не так важны для СУБД, и журнал структурированного хранилища приводит к дополнительным преимуществам для базы данных.
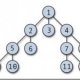
Основа организации системы структурированного журнала хранения данных, как следует из названия, это журнал — то есть, все происходит путем последовательной записи данных. Всякий раз, когда у вас есть новые данные для записи, вместо того чтобы найти место для него на диске, вы просто добавляете его в конце журнала. Индексация данных осуществляется путем обработки метаданных: обновление метаданных также происходят в журнале. Это может показаться неэффективным, но на диске структуры индексов, представляют из себя B-деревья, как правило, они очень широкие, поэтому число узлов индекса нам необходимо обновить с каждой записью, как правило, очень малы. Давайте посмотрим на простом примере. Мы начнем с журналов, содержащих только один элемент данных, а также индекс узла, который ссылается на него:

Пока все хорошо. Теперь предположим, что мы хотим добавить второй элемент. Мы добавляем новый элемент в конце журнала, и обновленную версию указателя:
Исходная запись с индексом (A) все еще находится в файле, но он больше не используется: она была заменена новой записью A', которая относится к оригинальной копии Foo, а также к новой записи Bar. Когда хоти прочитать из нашей файловой системы, мы находим индекс корневого узла, и использует его как было бы в любой другой системе.
Быстрый поиск корневого индекса. При простом подходе можно было бы просто посмотреть на последний блок в журнале, так как последнее, что мы записываем всегда корневой индекс. Однако, это не идеал, так как вполне возможно, что на момент чтения индекса, другой процесс добавляет середину журнала. Мы можем избежать этого, имея единый блок — скажем, в начале журнала — который содержит указатель на текущий корневой узел. Всякий раз, когда мы будем обновлять журнал, мы будем переписывать первую запись, чтобы убедиться, что он указывает на новый корневой узел.
Далее, давайте посмотрим, что происходит, когда мы обновляем элемента. Скажем, у нас изменить Foo:
Мы начали записывать совершенно новую копию Foo в конце журнала. Затем мы снова обновили индекс узлов (только в этом примере) и также записали его в конце журнала. Еще раз, старая копия Foo остается в журнале, но обновленный индекс просто больше на него не ссылается.
Вы, наверное, поняли, что эта система не является устойчивым на неопределенный срок. В какой-то момент старые данные будут просто занимать пространство. В файловой системе, это рассматривается как кольцевой буфер, перезапись старых данных. Когда это произойдет, данные, которые остаются в силе просто добавляются в журнал снова, как будто они были только что записаны, а не нужные старые копии будут перезаписаны.
Source: habrahabr.ru