Хранение Данных в Таблицах
 До недавнего времени все СУБД, работающие со структурированными данными (и не только их), можно было разделить на 2 категории: хранящие записи в построчном формате и хранящие записи в поколоночном формате. Это фундаментальное отличие, влияющее на то, как строки таблиц выглядят на уровне внутренних механизмов хранения СУБД. Долгое время СУБД Teradata относилась к первой группе, но с выходом 14-й версии представилась возможность определять, как хранить данные конкретной таблицы – в виде колонок или строк. Таким образом, появилось гибридное хранение. В этой статье мы хотим рассказать о том, зачем это нужно, как это реализовано и какие преимущества дает.
До недавнего времени все СУБД, работающие со структурированными данными (и не только их), можно было разделить на 2 категории: хранящие записи в построчном формате и хранящие записи в поколоночном формате. Это фундаментальное отличие, влияющее на то, как строки таблиц выглядят на уровне внутренних механизмов хранения СУБД. Долгое время СУБД Teradata относилась к первой группе, но с выходом 14-й версии представилась возможность определять, как хранить данные конкретной таблицы – в виде колонок или строк. Таким образом, появилось гибридное хранение. В этой статье мы хотим рассказать о том, зачем это нужно, как это реализовано и какие преимущества дает.
Что такое Teradata Columnar?
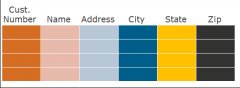
Прежде чем говорить о формате хранения по колонкам, скажем пару слов о том, как мы обычно храним данные по строкам. Возьмем реляционную таблицу, в которой есть колонки и строки:Как мы пишем на диск данные этой таблицы в случае ее строчного формата? Сначала пишем первую строку, затем вторую, третью и так далее:
 Как минимизировать нагрузку на дисковую систему при чтении этой таблицы? Можно использовать разные методы доступа к ней:
Как минимизировать нагрузку на дисковую систему при чтении этой таблицы? Можно использовать разные методы доступа к ней:
- Доступ по индексу – если нужно прочитать лишь несколько строк.
- Доступ к отдельным ее партициям (секциям) – если таблица очень большая (например, приведены транзакции за несколько лет, но нужно прочитать данные только за последние несколько недель). Это партиции по строкам.
- Полное чтение таблицы – если нужно прочитать большой процент от числа ее строк.
То есть минимизация нагрузки на дисковую систему основана на том, что нам требуется прочитать не всю таблицу, а только отдельные ее строки.
А как насчет колонок? Если SQL-запрос использует не все колонки таблицы, а только некоторые из них? При чтении строк мы читаем с диска каждую строку полностью. Если в таблице 100 колонок, а конкретному SQL-запросу нужны лишь 5 из них, то мы вынуждены прочитать с диска 95 колонок, которые SQL-запрос не использует.
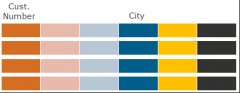
Такое разбиение таблицы на колонки создает партиции по колонкам. Если запросу нужны только отдельные колонки, то мы читаем с диска только нужные партиции по колонкам, существенно сокращая количество операций ввода-вывода при чтении данных, которые нужны SQL-запросу.
Интересная особенность такого подхода состоит в том, что партиции по строкам и партиции по колонкам можно использовать одновременно в одной и той же таблице, иными словами – партиции внутри партиций. Сначала заходим в нужные партиции по колонкам, затем внутри них читаем только нужные партиции по строкам.
Суммируя вышесказанное, Teradata Columnar – это метод хранения данных в СУБД Teradata, который позволяет таблицам одновременно использовать два метода партиционирования:
- Горизонтальные партиции – по строкам
- Вертикальные партиции – по колонкам
 Преимущества Teradata Columnar
Преимущества Teradata Columnar
Преимущества следующие:
- Увеличение производительности запросов – за счет чтения только отдельных партиций по колонкам, исключая необходимость считывать все данные в строках таблицы. Это как раз то, с чего мы начали нашу статью.
- Эффективное автоматическое сжатие данных с использованием механизма автоматической компрессии. А вот это дополнительная приятная возможность, которая открывается при хранении данных по колонкам: в этом случае данные намного удобнее сжимать. Некоторые даже ставят это преимущество на первое место, и вполне обоснованно.
Оба эти пункта ведут к сокращению нагрузки на дисковую систему. В первом случае мы читаем меньшее количество данных, поэтому совершаем меньшее количество операций ввода-вывода. Во втором случае таблица занимает меньше места на диске, и, как следствие, чтобы ее прочитать, требуется меньшее количество операций ввода-вывода.
Source: habrahabr.ru