Архитектура Хранения Данных
Архитектура хранения данных в Facetz.DCA
Сентябрь 6, 2017 – 09:54
 Facetz.DCA хранит данные об активности более 600 млн. анонимизированных пользователей и отдает интересы пользователя в среднем менее, чем за 10 мс. Необходимость в такой высокой скорости диктуется процессом показа рекламы по технологии Real Time Bidding — ответ на запрос о показе должен быть дан в течение 50 мс.
Facetz.DCA хранит данные об активности более 600 млн. анонимизированных пользователей и отдает интересы пользователя в среднем менее, чем за 10 мс. Необходимость в такой высокой скорости диктуется процессом показа рекламы по технологии Real Time Bidding — ответ на запрос о показе должен быть дан в течение 50 мс.
При построении архитектуры хранения данных в DMP решаются две задачи: хранение информации о пользователях для последующего анализа и хранение результатов анализа. Решение первой должно обеспечивать высокую пропускную способность при доступе к данным — истории пользовательской активности. Вторая задача требует обеспечить минимальные задержки, те самые 10 мс. Оба решения должны быть хорошо горизонтально масштабируемы.
Хранение сырых данных
В Facetz.DCA в сутки поступают несколько терабайт логов, для их хранения мы используем распределенную файловую систему HDFS. Обработка данных происходит с использованием парадигмы MapReduce. Доступ к сырым данным организован через Apache Hive — библиотеку, транслирующую SQL-запросы в MapReduce задачи. Более подробно об этих технологиях можно прочитать в наших статьях — этой и этой.Хранения профилей пользователей
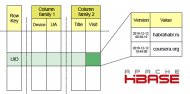
В Facetz для хранения данных об активности пользователей используется Apache HBase. Информация о посещенных сайтах попадает туда через Map-Reduce сервис Loader, читающий сырые логи с HDFS, а также потоково через Kafka. В HBase данные хранятся в таблицах, ключом является id пользователя, колонки — различные виды фактов, например url посещенной страницы, ее название, useragent или ip-адрес. Колонки объединены в семейства — Column Family, данные из одной Column Family хранятся рядом, что увеличивает скорость выполнения GET-запросов, содержащих данные из нескольких колонок внутри одного семейства. Для каждой ячейки хранится множество версий, в нашей системы роль версии играет время события. Подробнее про Apache HBase Вы можете прочитать в этой статье.Source: habrahabr.ru